
近日有机会做了Hogan的三个经典测试:HPI(性格量表)、HDS(发展调查表)、MVPI(动机、价值观、及偏好调查问卷),还有SHL的OPQ,让我对这些经典测评报告有了新的一层认识。以前我就关注不少有意思的测评,这次的感受又有不同。

共同点
通过比对这两份测评,我发现以下的共同点:
1. 测评的时间较长
2. 测评题目重复多
首先说第一点,SHL的OPQ共104题,规定时间25分钟。再比如Hogan的三个测试,每个测试的题目在100道以上,每个耗时20分钟左右。可以看出题量确实不少,有关题量和客户感受的问题,其实在前期沟通时一直有问到。据此,我们可以发现,测评要保证效度的话,确实需要保证相当的题量。在这方面,我们可以比较DISC的测评,DISC的经典测评是32道题(迫选题),测了4个维度。基于Hogan三测评和OPQ的测评肯定在8个维度以上,也是合理的。
再来讲第二点,测评题目重复多。我做了这两个测评,发现有个共同点,就是测评的题目重复很多(因为题目多,测评维度有限)。所谓重复多,不仅是一模一样的多,而且相同意思的题目更多。譬如我举几个例子:
“重复性工作”相类似选项
我对重复性的工作感到无聊
我对重复性的工作感到厌烦
我很容易对重复性的工作感到沉闷
我对例行性工作感到厌烦
我不喜欢重复性的工作
我觉得例行工作十分沉闷
“有条不紊”相类似选项
我会把事情安排得妥当并有条不紊
我做事有条不紊(X2)
“领导者”相类似选项
我喜欢担任掌控的角色
我喜欢在团队中担任领导者的角色(X2)
我喜欢在团队中担任掌控的角色
我们可以看到这相类似选项出现的概率是相当的高,而且我是不完全统计。如果全部统计的话,那显然更多。为什么同一个选项出现的如此频繁,我估计有这么几个原因:
1.为了避免偶然性和减少掩饰性。做线上测评,容易被人诟病的就是这么两条,通过类似选项反复出现,减少偶然性、掩饰性。这里还有一种可能性,是通过反复出现选择项,在已经选择的项中间让你再优选(即类似AI智能给题的方式,有点像GRE,随着难度的增加题目也有变化),这一点还有待证实。
2.常模的需要。我们可以假设每一条类似选项是有分值的,通过分值的相加可以得出一个总分,于是通过数据量积累就有了正态分布曲线,就有了常模。这比单单一两道题的指向更容易积累数据和提升效度。

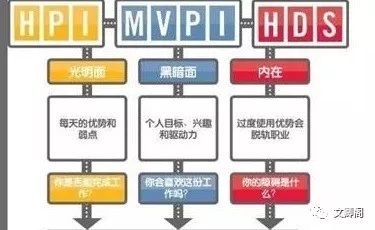
Hogan的特殊点
以上是共同点,接下来我再讲讲Hogan测评中特殊的几点。第一,是Hogan喜欢用双重否定句。譬如以下:
我很少为对我不公平的评论感到不快
在小组中,我不介意发表不受欢迎的意见
我不喜欢那些不愿意帮助有困难之人
我不喜欢不可预料的情况。
这种句型在OPQ当中也有见到,但是很少。Hogan中很多,比较烧脑。我个人的感觉是,如果不看仔细点,就要选错了。通过这样的句型,我们可以感受到Hogan的测评,相对而言是有些深度的(更在意测评者的分析思维,下面的例子中也可以看出)
第二点,Hogan的测评比较隐晦。所谓的隐晦,就是含蓄,不让你轻易看出测评的目的。这里有两种方法,第一种是我们心理学所谓投射,第二种是通过巧妙的句型安排(这我在以前也提过)。投射的具体体现方式,是通过朋友的选择、通过对环境的认识,来间接发现。
譬如以下:
我的大部分朋友会帮助那些需要帮忙的人。 (我是否乐于助人)
我的许多朋友是科学家。 (我是否对科学感兴趣)
(这两道题都是典型的“朋友选择”)
我不喜欢所有房子都很像的住宅区。 (我是否喜欢一致性)
(这道题属于“环境认识”)
这种投射的方式比较巧妙,通过“朋友”、“房子”,来看出我的个人偏好。
这是第一种,还有一种,是通过句型安排,譬如以下两句:
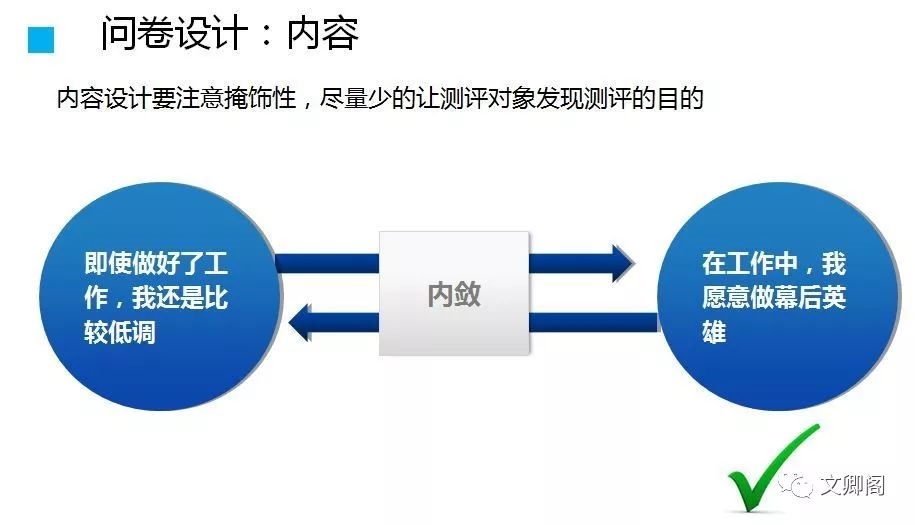
在某些情形下,我几乎什么都做的出来。 (我是否有底线)
一份好工作是这样的: 收入颇丰但需要做的事不多。 (我是否看重回报)
这两句话如果不仔细看,很容易第一选择就是自己本能的偏好(当然这也是出题者希望的)。所以,我们会看到,出题之妙,存乎一心。
以下是类似的例子,看下图:
好了,从题目本身我们就可以搜集到如此多的信息。可见,通过比较不同测评问卷的细微异同,我们可以找到很多背后的逻辑和原理。类似Hogan三测评和OPQ,都是经典的测评,传说OPQ花了4年才研发成功,这里面的底层逻辑是十分深厚的,也是我们值得学习的。
